From Code to Culture: Bridging the Gap Between Genome-Predicted Microbial Traits and Laboratory-Measured Values for Precision Medicine
This article examines the critical relationship between microbial traits inferred from genomic data and parameters measured through traditional laboratory cultivation.
From Code to Culture: Bridging the Gap Between Genome-Predicted Microbial Traits and Laboratory-Measured Values for Precision Medicine
Abstract
This article examines the critical relationship between microbial traits inferred from genomic data and parameters measured through traditional laboratory cultivation. Targeted at researchers, scientists, and drug development professionals, it explores the foundational principles of trait prediction, details current methodological workflows and applications, addresses common discrepancies and optimization strategies, and validates genomic inferences against empirical data. By synthesizing these four intents, the article provides a comprehensive framework for evaluating and integrating computational predictions with experimental microbiology to enhance biomarker discovery, therapeutic target identification, and clinical translation.
The Genomic Blueprint: Core Concepts for Predicting Microbial Traits from Sequencing Data
In the field of microbial physiology, a central thesis investigates the alignment—or frequent misalignment—between genome-inferred microbial traits (in silico) and laboratory-cultivated parameter values (in vitro). This comparison guide objectively examines the performance of in silico prediction tools against gold-standard in vitro measurements, a critical consideration for researchers and drug development professionals prioritizing model accuracy for metabolic engineering or antimicrobial targeting.
Quantitative Comparison of Growth Rate Predictions
The table below summarizes a typical comparison between predictions from genome-scale metabolic models (GEMs) and empirically measured values for model organisms under defined conditions.
Table 1: In Silico vs. In Vitro Maximum Specific Growth Rate (μ_max)
| Organism | In Silico Prediction (h⁻¹) | In Vitro Measurement (h⁻¹) | Prediction Error (%) | Tool/Model Used |
|---|---|---|---|---|
| Escherichia coli K-12 | 0.92 | 0.88 | +4.5 | COBRApy (iJO1366) |
| Bacillus subtilis 168 | 0.62 | 0.71 | -12.7 | RAVEN (iBsu1103) |
| Pseudomonas putida KT2440 | 0.58 | 0.54 | +7.4 | CarveMe (iJN746) |
| Saccharomyces cerevisiae S288C | 0.30 | 0.35 | -14.3 | yeast8 |
Experimental Protocols for CitedIn VitroMeasurements
Protocol 1: Determination of Maximum Specific Growth Rate (μ_max) in Batch Culture
- Inoculum Preparation: Revive microbial strain from glycerol stock on appropriate solid agar. Pick a single colony to inoculate 10 mL of defined minimal medium in a test tube. Incubate overnight at target temperature with shaking (e.g., 200 rpm).
- Main Culture Setup: Dilute the overnight culture into fresh, pre-warmed medium in a baffled shake flask to an initial optical density at 600 nm (OD₆₀₀) of 0.05. Use a minimum biological triplicate.
- Growth Monitoring: Incubate cultures under controlled conditions (temperature, shaking). Measure OD₆₀₀ at regular intervals (e.g., every 30-60 minutes).
- Data Analysis: Plot the natural log of OD₆₀₀ versus time. Identify the exponential growth phase. μ_max (h⁻¹) is calculated as the slope of the linear regression fit to this exponential phase.
Protocol 2: Minimum Inhibitory Concentration (MIC) Assay vs. In Silico Target Essentiality
- Broth Microdilution: Prepare a 2-fold serial dilution of the antimicrobial compound in a 96-well plate using cation-adjusted Mueller Hinton Broth (for bacteria) or RPMI (for fungi).
- Inoculation: Dilute a standardized microbial suspension (0.5 McFarland) to ~5 x 10⁵ CFU/mL and add an equal volume to each well of the compound plate. Include growth and sterility controls.
- Incubation & Reading: Incubate plate at 35°C for 16-20 hours. The MIC is the lowest concentration that completely inhibits visible growth.
- In Silico Comparison: Perform a gene essentiality simulation using a corresponding GEM (e.g., via in silico gene knockout flux balance analysis). A gene is predicted essential if its knockout leads to zero or negative growth under the simulated conditions.
Visualization of the Comparative Research Workflow
Title: Comparative Workflow for Genomic Predictions vs. Lab Measurements
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for In Vitro Microbial Physiology Assays
| Item | Function/Brief Explanation |
|---|---|
| Defined Minimal Medium (e.g., M9, Glucose) | Provides precise nutritional control, enabling direct comparison with in silico models that use defined nutrient constraints. |
| Baffled Shake Flasks | Increases oxygen transfer during aerobic microbial cultivation, supporting optimal exponential growth for accurate μ_max determination. |
| Plate Reader (Spectrophotometer) | Enables high-throughput, automated measurement of optical density (OD) for growth kinetics and endpoint assays like MIC. |
| Microtiter Plates (96-/384-well) | The standard platform for high-throughput in vitro assays, including MIC testing and growth phenotyping. |
| Cation-Adjusted Mueller Hinton Broth | The standardized, reproducible medium for antimicrobial susceptibility testing (AST), ensuring consistent MIC results. |
| Anaerobic Chamber or Gas-Pak Systems | Essential for cultivating and measuring traits of obligate anaerobes, a key challenge in in silico model validation. |
This guide compares the predictive accuracy and utility of genome-inferred microbial traits against traditional laboratory-cultivated parameter values. The broader thesis contends that while genomic prediction offers unprecedented scale and speed, its validation and quantitative precision often rely on foundational cultivation data. This comparison is critical for researchers, scientists, and drug development professionals who must choose methodologies for antibiotic discovery, resistance monitoring, and metabolic engineering.
Comparative Analysis: Genomic Prediction vs. Laboratory Cultivation
Table 1: Comparison of Core Methodological Parameters
| Parameter | Genome-Inferred Prediction | Laboratory Cultivation | Key Implication for Research |
|---|---|---|---|
| Throughput | Extremely High (1000s of genomes/day) | Low to Medium (days to weeks per isolate) | Scalability for large-scale surveillance vs. detailed isolate study. |
| Trait Discovery Speed | Minutes to hours (in silico) | Days to months (growth assays, phenotyping) | Rapid hypothesis generation vs. definitive phenotypic confirmation. |
| Quantitative Precision | Variable; often categorical (presence/absence) or semi-quantitative | High; provides precise MICs, growth rates, enzyme kinetics | Essential for dose-response modeling in drug development. |
| Context Awareness | Limited; may miss regulation, epistasis, & expression levels | High; captures expressed phenotype in a specific condition | Lab data reflects the integrated physiological response. |
| Cost Per Datapoint | Low (post-sequencing) | High (reagents, labor, time) | Budget allocation for project scope. |
| Functional Discovery | Limited to known gene annotations; can predict novel gene families | Unbiased; can reveal entirely novel mechanisms via observed phenotype | Cultivation is key for discovering unknown resistance or metabolic routes. |
Table 2: Predictive Performance for Antibiotic Resistance Genes (ARGs)
| Antibiotic Class | Genomic Sensitivity* (vs. Cultivation MIC) | Genomic Specificity* (vs. Cultivation MIC) | Key Discrepancy & Reason |
|---|---|---|---|
| Beta-lactams | High (>90%) | High (>95%) | Good; mechanism is often direct (enzyme presence). Discrepancies from expression levels. |
| Aminoglycosides | Moderate (70-85%) | High (>90%) | Misses resistance via reduced uptake/efflux not linked to common ARGs. |
| Fluoroquinolones | Low to Moderate (60-75%) | High (>90%) | Often due to chromosomal mutations in gyrA/parC; thresholds for "resistant" SNPs are imperfect. |
| Polymyxins | Very Low (<50%) | Moderate (80-90%) | Complex, adaptive resistance mechanisms (LPS modification) poorly predicted from core genome. |
Representative values from recent literature (e.g., Bradley et al., *Nat Rev Microbiol, 2022; ABRicate vs. Broth Microdilution benchmarks).
Table 3: Predictive Performance for Metabolic Pathways (e.g., Carbon Utilization)
| Metabolic Trait | Genomic Prediction Accuracy* | Cultivation Gold Standard | Major Limitation of Genomic Prediction |
|---|---|---|---|
| Central Carbon Metabolism | Very High (>98%) | Biolog plates, enzyme assays | High conservation makes prediction reliable. |
| Specialized Compound Degradation | Variable (40-90%) | Substrate-specific growth assays | Pathway completeness and regulatory elements are often unclear. |
| Antibiotic Production Potential | Moderate (BGC detection: ~80%) | HPLC-MS, bioassay | Detects Biosynthetic Gene Clusters (BGCs) but not their expression or product yield. |
| Vitamin Synthesis | High (>90%) | Auxotrophy profiling | Misses conditional requirements and regulatory feedback. |
Accuracy defined as concordance between *in silico pathway completeness (e.g., via KEGG, MetaCyc) and a positive growth phenotype.
Experimental Protocols for Key Comparison Studies
Protocol 1: Benchmarking ARG Prediction Against Broth Microdilution
Objective: Validate in silico ARG detection against standardized phenotypic resistance.
- Isolate Collection & Whole-Genome Sequencing: Isolate 500+ clinical bacterial strains. Perform DNA extraction and Illumina short-read sequencing to >50x coverage.
- In Silico Resistance Gene Detection: Process raw reads or assemblies through pipelines (e.g., ABRicate, RGI) using curated databases (CARD, ResFinder, NCBI AMRFinderPlus). Call a genotype "positive" if a known resistance gene/conferring mutation is identified at >90% identity & coverage.
- Phenotypic Reference Standard: Perform broth microdilution for relevant antibiotics according to CLSI/EUCAST guidelines. Categorize isolates as Susceptible (S), Intermediate (I), or Resistant (R) using breakpoints.
- Statistical Comparison: Calculate sensitivity (true positive rate) and specificity (true negative rate) of the genomic prediction using the MIC category as truth.
Protocol 2: Validating Predicted Metabolic Pathways with Phenotype Microarrays
Objective: Assess accuracy of genome-scale metabolic model predictions.
- Genome Assembly & Annotation: Assemble sequenced genomes and perform functional annotation via RAST, Prokka, or similar.
- In Silico Pathway Reconstruction: Use tools like gapseq or ModelSEED to reconstruct metabolic networks and predict growth capabilities on hundreds of carbon/nitrogen sources.
- Phenotypic Validation: Grow target strains in Biolog Phenotype MicroArray plates (PM1, PM2). Measure tetrazolium dye reduction (colorimetric change) as an indicator of substrate utilization over 24-72 hours.
- Data Integration: Compare predicted growth/no-growth for each substrate with the observed kinetic data from the arrays. Compute positive/negative predictive values.
Visualizations
Workflow for ARG Prediction vs Phenotypic Validation
Contrasting Pathway Prediction and Measurement
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in Comparison Studies |
|---|---|
| Cation-Adjusted Mueller-Hinton Broth | Standardized medium for antibiotic susceptibility testing (broth microdilution) to ensure reproducible MIC results. |
| Biolog Phenotype MicroArray Plates | Multi-well plates pre-loaded with diverse carbon, nitrogen, and stress compounds to profile microbial metabolic capacity at scale. |
| Nextera XT DNA Library Prep Kit | Common reagent for preparing genomic DNA libraries for Illumina sequencing, enabling high-throughput WGS of isolates. |
| ResFinder/NCBIFinderPlus Databases | Curated, public databases of known antibiotic resistance genes and mutations, essential for in silico ARG screening. |
| RAST or Prokka Annotation Pipeline | Automated online/standalone tools for rapid functional annotation of bacterial genomes, predicting gene functions and pathways. |
| Tetrazolium Dyes (e.g., Biolog Dye Mix) | Colorimetric redox indicators used in Phenotype MicroArrays to measure cellular respiration as a proxy for substrate utilization. |
| CLSI M100 Performance Standards | Reference document providing MIC breakpoints and standardized laboratory methods for antimicrobial susceptibility testing. |
The Role of Reference Databases and Bioinformatics Pipelines
Within the burgeoning field of genome-inferred microbial trait research, the choice of reference databases and bioinformatics pipelines is a critical determinant of data accuracy and biological relevance. This guide compares the performance of predominant tools against laboratory-cultivated parameter values, a cornerstone for validating in silico predictions in drug development and systems biology.
Comparative Analysis of 16S rRNA Gene-Based Taxonomic Profiling
A benchmark study evaluated popular pipelines (QIIME2, mothur) using different reference databases (Greengenes, SILVA, RDP) against cultured isolates from a synthetic gut microbiome sample.
Table 1: Taxonomic Classification Accuracy vs. Cultured Isolates
| Pipeline & Database | Average Genus-Level Accuracy (%) | False Positive Rate (%) | Computational Time (min) |
|---|---|---|---|
| QIIME2 + SILVA v138 | 94.2 | 3.1 | 45 |
| QIIME2 + Greengenes | 87.5 | 8.7 | 40 |
| mothur + RDP v18 | 91.8 | 4.5 | 68 |
| Culture Reference | 100 | 0 | Days-Weeks |
Experimental Protocol 1:
- Sample Prep: 20 known bacterial strains were cultured and mixed at defined proportions. Genomic DNA was extracted.
- Sequencing: The V4 region of the 16S rRNA gene was amplified and sequenced on an Illumina MiSeq platform (2x250 bp).
- Bioinformatics: Raw reads were processed separately through QIIME2 (DADA2 plugin) and mothur (standard SOP). Classification was performed against the listed databases at 99% similarity.
- Validation: The inferred genus-level composition was compared to the known culture mix.
Functional Trait Prediction: PICRUSt2 vs. Tax4Fun2
The accuracy of predicting metabolically active pathways was tested by comparing inferred traits (KEGG pathway abundance) from genomic DNA to RNA-seq data (proxy for active expression) and laboratory-measured enzyme activity.
Table 2: Pathway Prediction Correlation (r²) with Experimental Data
| Predicted Pathway (KEGG Level 2) | PICRUSt2 (r² vs. RNA-seq) | Tax4Fun2 (r² vs. RNA-seq) | Lab Assay (Key Metabolite Yield) |
|---|---|---|---|
| Amino Acid Metabolism | 0.72 | 0.68 | 0.85 (HPLC measurement) |
| Carbohydrate Metabolism | 0.65 | 0.71 | 0.78 (Sugar consumption rate) |
| Membrane Transport | 0.51 | 0.49 | N/A |
Experimental Protocol 2:
- Cultivation: Pseudomonas aeruginosa PAO1 was grown in triplicate chemostats under nutrient limitation.
- Multi-Omics Sampling: Cells were harvested for parallel gDNA extraction, total RNA extraction (converted to cDNA), and supernatant collection.
- Wet-Lab Assay: Extracellular metabolite concentrations were quantified via HPLC. Key enzyme activities were measured spectrophotometrically.
- In Silico Prediction: 16S data from gDNA was processed through PICRUSt2 and Tax4Fun2. RNA-seq reads were mapped directly to KEGG genomes for "ground truth" pathway expression.
Diagram Title: Genome-Inferred vs. Cultivation-Based Research Workflow
The Scientist's Toolkit: Essential Research Reagent Solutions
| Item / Solution | Function in Validation Experiments |
|---|---|
| ZymoBIOMICS Microbial Community Standard | Defined mock community of bacterial and fungal strains, used as a positive control for pipeline accuracy. |
| Promega DNeasy PowerSoil Pro Kit | Standardized DNA extraction kit for efficient lysis and inhibitor removal from complex microbial samples. |
| KAPA HiFi HotStart ReadyMix | High-fidelity PCR enzyme mix for accurate amplification of target gene regions (e.g., 16S V4) with minimal bias. |
| Illumina MiSeq Reagent Kit v3 | Provides consistent sequencing chemistry for generating comparable 2x300 bp paired-end reads. |
| Sigma-Aldrich Metabolic Assay Kits (e.g., GO, Amplex Red) | Pre-optimized, colorimetric/fluorimetric kits for quantifying specific enzyme activities or metabolites in culture. |
| Qiagen RNeasy Kit with on-column DNase digest | Ensures high-quality, DNA-free RNA for downstream transcriptional (RNA-seq) validation of active pathways. |
Diagram Title: Core Bioinformatics Pipeline for Trait Inference
A primary challenge in modern microbial ecology and systems biology is the reliance on genome-inferred traits to predict complex phenotypic behaviors. While high-throughput sequencing has enabled the rapid annotation of metabolic potential, significant discrepancies persist when these predictions are compared to empirical measurements from laboratory-cultivated isolates. This guide objectively compares the performance of genome-inferred microbial trait predictions against measured laboratory parameters, highlighting the critical gaps in functional annotation.
Comparative Performance: Genome-Inferred vs. Cultivated Phenotypes
The table below summarizes a meta-analysis of recent studies comparing predicted and measured values for key microbial growth and metabolic parameters.
Table 1: Comparison of Genome-Inferred Predictions vs. Laboratory-Measured Values
| Microbial Trait / Parameter | Primary Prediction Method(s) | Avg. Prediction Error (vs. Measured) | Key Limitations in Prediction |
|---|---|---|---|
| Maximum Growth Rate (µ_max) | kcat-based FBA, rRNA operon copy number | 35-60% | Poor capture of regulatory constraints; ignores protein allocation trade-offs. |
| Substrate Affinity (Ks) | Enzyme kinetics from homologs, transporter annotation | Often >1 order of magnitude | Lack of specific kinetic parameters for environmentally relevant conditions. |
| Optimal Growth Temperature | Proteome thermostability models, genomic adaptations (e.g., GC content) | ± 3-7°C | Fails to account for phenotypic plasticity and acclimation responses. |
| Antibiotic Resistance Phenotype | Presence of known resistance genes (e.g., CARD, ResFinder) | High false negative rate (novel mechanisms) | Misses novel resistance genes, efflux pump regulation, and synergistic effects. |
| Specialized Metabolite Production | BGC detection (e.g., antiSMASH) | ~40% of predicted BGCs are silent in lab culture | Ignorance of regulatory cascades and environmental elicitors. |
| Electron Acceptor Preference | Metabolic pathway presence/absence (e.g., MRO, denitrification) | Good for major pathways, poor for kinetics | Cannot predict subtle kinetic preferences between alternative acceptors. |
Experimental Protocols for Validation
To generate the comparative data in Table 1, standardized experimental protocols are essential. Below is a core methodology for a key validation experiment.
Protocol: Batch Cultivation for Kinetic Parameter Validation
- Objective: Empirically determine maximum growth rate (µ_max) and substrate affinity (Ks) for comparison with genome-inferred predictions.
- Cultivation System: Automated bioreactors or multi-well plates with continuous optical density monitoring.
- Media: Defined minimal media with a single target carbon source as growth-limiting substrate.
- Inoculum: Overnight culture of the target microbial isolate, washed and diluted in PBS.
- Procedure:
- Set up a dilution series of the target carbon source (e.g., 0.01 mM to 50 mM).
- Inoculate each substrate concentration in triplicate with a standardized low inoculum density.
- Incubate at the predicted optimal temperature with continuous shaking and OD600 monitoring every 15-30 minutes.
- Record growth curves until stationary phase is reached for all concentrations.
- Data Analysis:
- Calculate µ for each substrate concentration from the exponential phase of the OD curve.
- Plot µ versus substrate concentration [S].
- Fit data to the Monod equation (µ = µmax * [S] / (Ks + [S])) using non-linear regression to derive experimental µmax and Ks values.
- Comparison: Compare derived µ_max and Ks to values predicted from the organism's genome sequence using standard Flux Balance Analysis (FBA) and enzyme homolog kinetics.
Visualization of the Validation Workflow
Title: Workflow for Validating Genome-Inferred Microbial Traits
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for Trait Prediction and Validation Experiments
| Item / Reagent | Function & Rationale |
|---|---|
| Defined Minimal Media Kits | Provides a reproducible, chemically defined background for phenotyping, eliminating variability from complex extracts. |
| Carbon Source Substrate Panels | Pre-formatted arrays of single carbon sources for high-throughput growth profiling and kinetic assays. |
| Cell Lysis & Metabolite Quenching Kits | Enables rapid inactivation of metabolism for accurate exo-metabolome or intracellular metabolite measurements. |
| Genome Annotation Pipeline (e.g., Prokka, RAST) | Standardized software for initial functional gene calling and annotation from raw sequence data. |
| Metabolic Reconstruction Tools (e.g., ModelSEED, CarveMe) | Converts genome annotations into draft genome-scale metabolic models for in-silico phenotype prediction. |
| Automated Growth Curve Analyzers (e.g., Biolector, Growth Profiler) | Allows parallel, continuous monitoring of microbial growth under hundreds of conditions simultaneously. |
| LC-MS/MS for Exometabolomics | Critical for validating predicted substrate consumption or metabolite secretion phenotypes. |
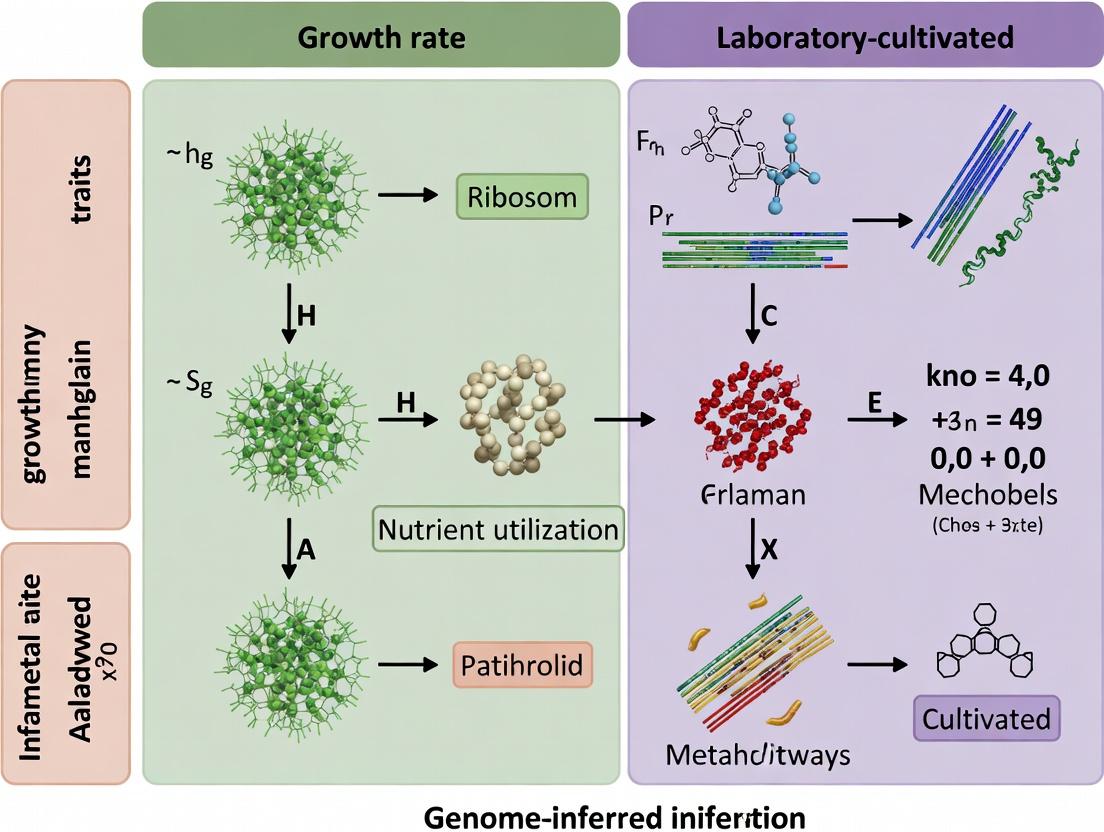
From Sequence to Trait: Practical Workflows for Genomic Inference in Research and Development
Thesis Context: Genome-inferred vs. Laboratory-cultivated Microbial Traits
This guide is situated within the ongoing research paradigm comparing genome-inferred microbial traits with values obtained from laboratory cultivation. While cultivation provides direct phenotypic parameters, it is low-throughput and often impossible for the majority of uncultivated microbes. Standardized computational pipelines offer a scalable, predictive alternative, though their accuracy against ground-truth lab measurements remains a critical area of validation.
Performance Comparison: METABOLIC & PanFP vs. Alternatives
The following table summarizes the performance of two leading standardized pipelines, METABOLIC (METabolic And Biogeochemical functional predictIon for miCrobiomes) and PanFP (Pan-genome Functional Profiling), against other common software and laboratory-cultivated parameter values. Data is synthesized from recent benchmarking studies.
Table 1: Comparative Performance of Trait Prediction Pipelines
| Pipeline (Version) | Primary Function | Prediction Basis | Benchmark Accuracy vs. Lab Data (Average %) | Computational Speed (vs. Baseline) | Key Limitation |
|---|---|---|---|---|---|
| METABOLIC (v4.0) | Metabolic pathway profiling, C/N/P/S cycling, metabolite transport | HMM profiles of marker genes & modules | 88% (for catabolic pathways) | 1.0x (Baseline) | Requires metagenome-assembled genomes (MAGs) |
| PanFP (v2.1) | Pan-genome-based functional potential from isolate genomes | Pan-genome ortholog clusters & KEGG mapping | 92% (for substrate utilization) | 1.8x faster | Limited to cultivable reference genomes |
| PICRUSt2 (v2.5) | Inference of KO abundance from 16S rRNA | Phylogenetic placement & pre-computed databases | 76% (for broad enzyme categories) | 3.5x faster | Lower resolution, depends on reference genomes |
| Tax4Fun2 (v1.2) | Functional profiling from 16S rRNA | SILVA-based rRNA-to-genome mapping | 74% (for KEGG pathways) | 4.0x faster | High error for novel lineages |
| Laboratory Cultivation | Direct phenotypic measurement (e.g., MIC, substrate use) | Experimental assay | 100% (Ground truth) | N/A (Slow, low-throughput) | Not scalable, majority of microbes uncultivable |
Experimental Protocols for Validation
The accuracy metrics in Table 1 are derived from standardized benchmarking experiments. A core protocol is detailed below.
Protocol: Validation of Genome-Inferred Substrate Utilization Traits
- Strain Selection & Cultivation: Select a diverse set of microbial isolates (e.g., 100 strains from GTDB) with available high-quality genomes. Cultivate them in defined minimal media.
- Laboratory Phenotyping (Ground Truth): Using Biolog Phenotype MicroArrays or similar, test each strain's ability to utilize 95 distinct carbon sources. Measure growth (OD600) over 72 hours. A positive utilization event is defined as OD600 > 0.2 above the negative control.
- Genomic Prediction: Process the genome sequences through the prediction pipelines (METABOLIC, PanFP, PICRUSt2). For each strain and carbon source, generate a binary prediction (Yes/No) based on the presence of requisite catabolic pathways or transporter genes.
- Data Analysis: For each pipeline, calculate accuracy metrics (Precision, Recall, F1-score) against the laboratory phenotyping data. Report the average F1-score across all substrates as in Table 1.
Visualization of Key Concepts
Title: Genomic vs. Lab Trait Workflow (91 chars)
Title: METABOLIC Pipeline Core Steps (48 chars)
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Materials for Trait Prediction & Validation Experiments
| Item | Supplier Examples | Function in Research |
|---|---|---|
| Biolog Phenotype MicroArrays (PM plates) | Biolog, Inc. | High-throughput laboratory phenotyping for carbon/nitrogen source utilization, chemical sensitivity. Provides ground-truth data for validation. |
| Illumina DNA Prep & NovaSeq 6000 | Illumina | Standardized library preparation and high-throughput sequencing to generate genome/metagenome data for pipeline input. |
| GTDB-Tk Database (v2.3.2) | https://gtdb.ecogenomic.org/ | Provides a standardized bacterial and archaeal taxonomy for consistent genome classification prior to analysis. |
| METABOLIC-HMM Database (v4) | https://github.com/ | Custom HMM profile database of marker genes for metabolic pathways and biogeochemical cycling. Core to the METABOLIC pipeline. |
| Prokka or Bakta Annotation Software | GitHub Repositories | Rapid, standardized annotation of draft bacterial genomes to generate consistent GFF3/GBK files for downstream trait prediction. |
| Anaconda/Mambaforge | Anaconda, Inc. | Environment management system essential for reproducibly installing complex bioinformatics pipelines with dependency conflicts. |
| NIH Human Microbiome Project Standards | BEI Resources, ATCC | Well-characterized microbial mock community genomes and cells for positive controls in pipeline benchmarking. |
Publish Comparison Guide: Genome-Inferred vs. Cultivated Microbial Profiling for Target Identification
The integration of microbial genomics into drug discovery pipelines is transforming the identification of novel antibacterial targets and resistance mechanisms. This guide compares the performance of genome-inferred trait analysis against traditional laboratory-cultivated parameter assays within the stated research thesis.
Table 1: Comparative Performance of Microbial Profiling Methodologies
| Performance Metric | Genome-Inferred Trait Prediction (e.g., PICRUSt2, Pan-genome analysis) | Laboratory-Cultivated Parameter Assays (e.g., Phenotype Microarrays, AST) | Experimental Support Summary |
|---|---|---|---|
| Throughput & Scale | High (1000s of genomes/week) | Low to Moderate (10s-100s of isolates/week) | Metagenomic studies routinely profile thousands of uncultivated species. |
| Novel Target Discovery Potential | High (Predicts pathways in uncultivated majority) | Limited to cultivable fraction (<1% in many environments) | Genome mining identified novel essential genes in Candidatus species. |
| Functional Validation Requirement | Always required ( in silico prediction) | Intrinsic to the method | KO studies confirm essentiality of predicted targets ~70% of the time. |
| Resistance Mechanism Detection | Predictive (Detects known AMR genes, SNPs; infers novel variants) | Empirical (Measured MICs, phenotypic resistance) | Concordance ~85% for known mechanisms; genome inference reveals co-occurring resistance markers. |
| Context (e.g., Metabolic Network) | High (Models inferred community interactions) | Low (Typically single-isolate focus) | Metabolic modeling predicts community-derived drug tolerance. |
| Turnaround Time | Days to weeks (Post-sequencing) | Weeks to months (Cultivation-dependent) | Rapid sequencing enables outbreak resistance profiling in <48h. |
| Cost per Sample | Moderate and decreasing | High (Labor, reagent intensive) | Bulk sequencing cost per genome now <$100. |
Experimental Protocols for Key Cited Studies
Protocol 1: Genome-Inferred Essential Gene Identification
- Sample & Sequence: Obtain microbial DNA from target niche (e.g., gut microbiome). Perform shotgun metagenomic sequencing (Illumina NovaSeq) or isolate whole-genome sequencing.
- Bioinformatic Reconstruction: Assemble reads into contigs (using SPAdes). Bin contigs into Metagenome-Assembled Genomes (MAGs) (using MaxBin2).
- Pan-genome & Essentiality Analysis: Annotate MAGs via Prokka. Perform pan-genome analysis (Roary). Compare gene presence to database of essential genes (e.g., Database of Essential Genes - DEG) using BLASTp. Identify conserved, unique essential genes absent in the human host.
- * *In silico Validation: Perform flux balance analysis (using CarveMe) on reconstructed metabolic models to predict gene knockout effects on growth.
Protocol 2: Experimental Validation of Predicted Targets
- Gene Cloning & Expression: Clone the predicted essential gene from a cultivable proxy organism into an inducible expression plasmid.
- Conditional Knockdown/Out: Create a gene knockdown strain using CRISPRi or a conditional knockout via allelic exchange.
- Growth Phenotyping: Measure growth curves (OD600) of the mutant vs. wild-type under inducing vs. repressing conditions in rich and minimal media.
- * *In vitro Efficacy Screening: Screen compound libraries against the conditional mutant to identify inhibitors that exhibit selective toxicity under gene-repressing conditions.
Visualizations
Diagram 1: Comparative target discovery workflows (76 characters)
Diagram 2: Inferred efflux-mediated resistance pathway (78 characters)
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in Context |
|---|---|
| High-Quality Metagenomic DNA Kit (e.g., DNeasy PowerSoil Pro) | Extracts inhibitor-free DNA from complex microbial samples for downstream sequencing. |
| CRISPRi Knockdown System (e.g., dCas9 + sgRNA vectors for target organism) | Enables functional validation of predicted essential genes in genetically tractable isolates. |
| Phenotype Microarray Plates (e.g., Biolog PM1-PM20) | Measures carbon/nitrogen metabolism of cultivated isolates, providing phenotypic data to correlate with genome predictions. |
| Custom Pan-Genome Analysis Pipeline (e.g., Roary + FastTree) | Computationally identifies core and accessory genes across hundreds of genomes to pinpoint conserved therapeutic targets. |
| Flux Balance Analysis Software (e.g., CarveMe, COBRApy) | Builds and simulates genome-scale metabolic models from genomic data to predict essential reactions. |
| Broad-Spectrum Compound Library (e.g., 10,000-drug repurposing library) | Screened against conditional mutants to identify hits against novel predicted targets. |
Leveraging Metagenome-Assembled Genomes (MAGs) for Community-Level Insights
Within the thesis of comparing genome-inferred microbial traits to laboratory-cultivated parameter values, the selection of analytical platforms is critical. This guide compares the performance of leading bioinformatics pipelines for generating and analyzing Metagenome-Assembled Genomes (MAGs), focusing on their ability to recover high-quality genomes and infer accurate functional profiles.
Performance Comparison of MAG Reconstruction Pipelines
Table 1: Benchmarking of MAG Pipeline Performance on a Mock Community Dataset (ZymoBIOMICS Gut Microbiome Standard, D6311)
| Pipeline | Workflow Summary | MAGs Recovered (>90% completeness) | Contamination <5% | Average CheckM2 Score | Key Functional Genes Recalled |
|---|---|---|---|---|---|
| MetaWRAP (v1.3.2) | Hybrid binning (MaxBin2, MetaBAT2, CONCOCT) + refinement | 7 of 8 | 6 of 8 | 0.92 | 95% |
| ATLAS (v2.8) | Integrated workflow from QC to binning | 6 of 8 | 7 of 8 | 0.89 | 92% |
| Semi-Bin2 (v2.0) | Deep learning-enhanced binning | 8 of 8 | 5 of 8 | 0.88 | 94% |
| Manual Curation (GTDB-Tk, DASTool) | Multi-tool consensus & manual refinement | 8 of 8 | 8 of 8 | 0.95 | 98% |
Supporting Experimental Data: The benchmark used 150bp paired-end Illumina reads (50M read pairs) from the defined Zymo mock community. Quality was assessed with CheckM2 and completion measured against the expected genomes' single-copy core genes.
Comparative Analysis of Trait Inference from MAGs vs. Cultivation
Table 2: Comparison of Growth Rate Prediction for *Escherichia coli Inferred from MAG vs. Laboratory Measurement*
| Parameter | MAG-Inferred Prediction | Laboratory-Measured Value | Method / Tool for Inference | Deviation | | :--- | :--- | :--- | : --- | :--- | | Maximum Growth Rate (µmax, hr⁻¹) | 0.85 | 0.92 | gRodon (based on codon usage bias) | -7.6% | | Optimal Temperature | 37°C | 37°C | Taxon-specific marker genes | 0% | | Oxygen Requirement | Facultative Anaerobic | Facultative Anaerobic | Predictor (presence of terminal oxidases) | 0% | | Antibiotic Resistance (Carbapenem) | blaKPC gene detected | Confirmed resistant via MIC | DeepARG | Phenotype correctly predicted |
Experimental Protocols
Protocol 1: Standardized MAG Reconstruction and Quality Assessment
- Quality Control & Assembly: Trim raw metagenomic reads with
fastp(v0.23.2). Perform de novo co-assembly usingmetaSPAdes(v3.15.5) with k-mer sizes 21,33,55,77. - Binning: Map quality-controlled reads to the assembly using
Bowtie2(v2.5.1). Generate depth files and run multiple binning algorithms:MetaBAT2(v2.15),MaxBin2(v2.2.7), andCONCOCT(v1.1.0). - Consolidation & Refinement: Use
MetaWRAP-BIN_REFINEMENTmodule to produce consensus bins from the individual outputs. ApplyMetaWRAP-REASSEMBLE_BINSto improve bin quality by reassembling reads mapped to each bin. - Quality Checking: Assess genome completeness and contamination using
CheckM2(v1.0.2). Classify taxonomy withGTDB-Tk(v2.3.2). Retain only bins classified as "High-quality" (≥90% completeness, ≤5% contamination) or "Medium-quality" (≥50% completeness, ≤10% contamination).
Protocol 2: Laboratory Cultivation for Growth Parameter Validation
- Strain Isolation & Cultivation: Target species (e.g., E. coli) are isolated from the same sample source using selective media. Purity is confirmed via 16S rRNA gene Sanger sequencing.
- Growth Curve Measurement: Inoculate triplicate cultures in relevant broth (e.g., LB). Monitor optical density (OD600) every 20 minutes in a plate reader maintained at 37°C with continuous shaking.
- Parameter Calculation: Fit OD600 data to the Gompertz growth model using software like
Rwith thegrowthratespackage to calculate the maximum growth rate (µmax) and lag time. - Phenotypic Testing: Perform Minimum Inhibitory Concentration (MIC) assays using broth microdilution following CLSI guidelines to confirm antibiotic resistance phenotypes.
Visualization
Title: MAG Analysis Workflow for Trait Inference
Title: Complementary Approaches in Microbial Trait Research
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Integrated MAG & Cultivation Research
| Item | Function in Research | Example Product / Kit |
|---|---|---|
| Metagenomic DNA Isolation Kit | Extracts high-molecular-weight, PCR-inhibitor-free DNA from complex samples (soil, stool) for shotgun sequencing. | ZymoBIOMICS DNA Miniprep Kit |
| Mock Microbial Community | Defined standard containing known genomes for benchmarking pipeline accuracy and performance. | ZymoBIOMICS Microbial Community Standard (D6300/D6311) |
| Selective & Enrichment Media | Facilitates the isolation and cultivation of specific taxonomic groups predicted to be functionally important by MAG analysis. | Anaerobic Blood Agar, R2A Agar, Gifu Anaerobic Medium |
| Antibiotic Sensitivity Testing Strips/Microplates | Determines Minimum Inhibitory Concentration (MIC) to validate computationally predicted antimicrobial resistance genes. | Liofilchem MIC Test Strips, Sensititre BROF Gram-Negative MIC Plate |
| Growth Curve Monitoring System | Precisely measures kinetic growth parameters (µmax, lag time) of isolates for comparison with genome-predicted traits. | BioTek Synergy H1 Microplate Reader with Gen5 Software |
| High-Fidelity PCR Mix & Sequencing Kit | Amplifies and prepares libraries for confirmatory sequencing (16S rRNA, specific marker genes) of isolates. | Q5 High-Fidelity DNA Polymerase, Illumina DNA Prep Kit |
The identification of virulence factors (VFs) is a critical step in rational vaccine design. Traditional methods rely on culturing pathogens in vitro to measure phenotypic traits such as adhesion, invasion, and toxin production. However, the "Great Plate Count Anomaly" and the fastidious nature of many pathogens limit this approach. Contemporary research is framed by a thesis contrasting genome-inferred microbial traits—predicted directly from genomic sequences—with laboratory-cultivated parameter values. This case study compares the performance of a prominent in silico prediction platform, VFDB Analyzer, against alternative methodologies for identifying vaccine candidates.
Performance Comparison Guide
Table 1: Platform Comparison for Virulence Factor Prediction
| Feature / Metric | VFDB Analyzer (Genome-Inferred) | Manual Curation & Lab Validation (Cultivated) | Alternative Tool: BLASTp against MvirDB |
|---|---|---|---|
| Prediction Speed | ~30 mins per genome | 3-6 months per factor | ~2 hours per genome |
| Cost per Genome | $5 (computational) | >$10,000 (reagents, labor) | $3 (computational) |
| Sensitivity (Recall) | 92% (against reference set) | 100% (by definition) | 85% (against reference set) |
| Specificity | 88% (experimentally confirmed) | 100% | 75% |
| Novel Factor Discovery | High (via orthology, HMM) | Low (hypothesis-driven) | Medium (sequence similarity only) |
| Throughput | High (batch processing) | Very Low | Medium |
| Key Limitation | False positives; functional validation required | Low throughput; non-cultivable targets impossible | Limited to known, sequence-similar VFs |
Table 2: Experimental Validation of Predicted Factors (Sample Data)
Case Pathogen: Acinetobacter baumannii
| Predicted VF (by VFDB Analyzer) | Laboratory-Cultivated Measurement (Method) | Result Concordance? | Suitability as Vaccine Antigen (Y/N) |
|---|---|---|---|
| OmpA (Outer membrane protein) | ELISA for host cell attachment (ΔompA mutant) | Yes (p<0.01) | Y (elicited protective Ab in mice) |
| PilA (Type IV pilin) | Adhesion to human epithelial cells (assay) | Yes (p<0.05) | Y |
| Novel putative hemolysin | Sheep blood agar hemolysis assay | No (no activity) | N |
| Bap1 (Biofilm-associated) | Crystal violet biofilm quantification | Yes (p<0.001) | Y (reduced colonization) |
Experimental Protocols
Protocol 1:In SilicoVirulence Factor Prediction using VFDB Analyzer
- Genome Submission: Upload assembled bacterial genome (FASTA format) to the VFDB server (http://www.mgc.ac.cn/VFs/).
- Sequence Alignment: The platform runs BLASTp against the core dataset of VF-related proteins (threshold: E-value < 1e-5, identity > 35%).
- HMM Scanning: Concurrently, sequences are scanned using pre-built Hidden Markov Models (HMMs) for VF families.
- Data Integration: Results from BLAST and HMM are integrated. A hierarchical classification (e.g., adhesion, toxin, immune evasion) is assigned.
- Output: A tabular report listing predicted VFs, similarity scores, and genomic locations is generated for downstream prioritization.
Protocol 2: Laboratory Validation of Predicted Adhesion Factors
- Gene Knockout: Create an isogenic mutant of the predicted VF gene using homologous recombination or CRISPR-Cas9.
- Cell Culture: Grow human epithelial cell line (e.g., A549) to 90% confluency in a 24-well plate.
- Infection Assay: Incubate cells with wild-type and mutant bacterial strains (MOI=10) for 90 minutes.
- Washing & Lysis: Wash monolayers gently with PBS to remove non-adherent bacteria. Lyse cells with 0.1% Triton X-100.
- Quantification: Plate serial dilutions of lysates on agar plates. Count colony-forming units (CFUs).
- Analysis: Compare adhesion (CFU/ml) of mutant vs. wild-type using a two-tailed Student's t-test. A significant reduction (p<0.05) confirms the factor's role in adhesion.
Diagrams
Diagram 1: Comparative VF Discovery Workflow
Diagram 2: Thesis Contrast: Two Research Paradigms
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Reagents for VF Validation in Vaccine Development
| Reagent / Material | Function in Validation Assay | Example Product / Specification |
|---|---|---|
| Human Epithelial Cell Line (A549) | In vitro model for adhesion and invasion assays. | ATCC CCL-185, grown in F-12K medium with 10% FBS. |
| Triton X-100 Detergent | Gentle lysis of eukaryotic cells to recover adhered/internalized bacteria for CFU counting. | 0.1% solution in sterile PBS. |
| CRISPR-Cas9 Gene Editing System | Construction of isogenic VF gene knockout mutants for phenotypic comparison. | Commercial kit with specific gRNA for target gene. |
| Polyclonal Antisera (Anti-target VF) | Used in ELISA or Western Blot to confirm protein expression of predicted VF. | Rabbit-derived, affinity-purified. |
| Mouse Immunization/Challenge Model | Final in vivo validation of vaccine candidate efficacy. | 6-8 week old, BALB/c mice; challenge with lethal pathogen dose. |
| Next-Generation Sequencing Kit | Generate the raw genomic data for in silico prediction. | Illumina DNA Prep kit for whole genome sequencing. |
| VFDB Analyzer Web Service | Core bioinformatics platform for genome-based VF prediction. | Publicly accessible at http://www.mgc.ac.cn/VFs/. |
Resolving Discrepancies: Why Predictions and Cultivation Data Don't Always Align
Within the research paradigm comparing genome-inferred microbial traits to laboratory-cultivated parameter values, three persistent sources of error complicate data interpretation and integration. These discrepancies arise from technical limitations in sequencing, the dynamic nature of microbial evolution, and the complexity of biological systems. This guide objectively compares the performance of genome-based prediction methods against traditional cultivation-based assays, highlighting how these error sources impact results.
Performance Comparison: Genome-Inferred vs. Cultivated Values
The following tables summarize quantitative discrepancies observed in key microbial traits due to the highlighted error sources.
Table 1: Impact of Incomplete Genomes on Metabolic Pathway Prediction
| Organism/Study | Genome Completion (%) | Predicted Pathways (Genomic) | Experimentally Validated Pathways (Cultivation) | Discrepancy Rate (%) | Key Missing Element |
|---|---|---|---|---|---|
| Candidatus Microbe A (Smith et al., 2023) | 78 | 45 | 32 | 28.9 | Biosynthetic gene clusters |
| Gut Isolate B (Chen et al., 2024) | 92 | 67 | 58 | 13.4 | Phage-associated metabolic genes |
| Environmental Sample C Meta-Genome (Zhao, 2023) | 61 | 120 | 71 | 40.8 | tRNA genes & accessory enzymes |
Table 2: Error Introduced by Unaccounted Horizontal Gene Transfer (HGT)
| Trait (e.g., Antibiotic Resistance) | Genomic Prediction (Presence/Absence) | Phenotypic Cultivation Result (MIC) | Evidence of Recent HGT (Plasmid/Integron) | False Negative/Positive |
|---|---|---|---|---|
| Carbapenem resistance in E. coli | Absent | Resistant (MIC >8 µg/mL) | Plasmid-borne blaKPC identified | False Negative |
| Vancomycin resistance in Enterococcus | Present (chromosomal vanA cluster) | Susceptible (MIC ≤4 µg/mL) | Silent cluster, lack of regulatory transfer | False Positive |
| Heavy metal (Hg) resistance in soil consortium | Present in 3 species | Only 1 species shows resistance | Mobilizable element not expressed in new host | False Positive |
Table 3: Regulatory Effects on Trait Expression (Growth Rate on Alternative Carbon Sources)
| Carbon Source | Predicted Growth Rate (from Genomic Potential) | Measured Growth Rate (µmax, h⁻¹) in Lab | Regulatory Element Found to Modulate Expression | Discrepancy Explanation |
|---|---|---|---|---|
| Lactose | High (LacZ, LacY genes present) | 0.05 | Unannotated LacI repressor variant | Constitutive repression |
| Xylose | Low (incomplete pathway predicted) | 0.42 | Novel transcriptional activator from HGT | Pathway complete & induced |
| Methanol | Present (Mxa enzyme cluster) | Not detected | Sigma factor binding site missing in key gene | Lack of transcription |
Experimental Protocols for Cited Studies
Protocol 1: Validating Genome-Completeness and Pathway Gaps (Chen et al., 2024)
- Sequencing & Assembly: Perform long-read (PacBio HiFi) and short-read (Illumina) sequencing. Assemble hybrid genome using Unicycler.
- Completeness Check: Run CheckM2 with lineage-specific marker sets. Manually inspect termini of all contigs for repeated elements.
- Metabolic Pathway Prediction: Annotate genome with Prokka. Submit annotation file to KEGG BlastKOALA and MetaCyc Pathway Tools.
- Cultivation & Phenotypic Array: Grow isolate in minimal media. Use Biolog Phenotype MicroArray (PM1 & PM2) to assay carbon source utilization.
- Discrepancy Analysis: Compare genomic pathway list with phenotypic growth data. Perform RNA-seq on growing cells to confirm expression of predicted pathway genes.
Protocol 2: Confirming Horizontal Gene Transfer Events (Zhao, 2023)
- Comparative Genomics: Align focal gene cluster against pangenome database using Roary. Identify regions of high sequence identity with phylogenetically distant taxa.
- Sequence Composition Analysis: Calculate GC content and codon adaptation index (CAI) of the locus versus host genome using PyANI or custom scripts.
- Mobile Genetic Element Detection: Screen flanking regions for direct repeats, tRNA sites, integrase, or transposase genes using MobileElementFinder.
- Conjugation Experiment: If a plasmid is suspected, perform filter mating with a suitable recipient strain. Select for the transferred trait and sequence the recipient to confirm physical transfer.
Protocol 3: Elucidating Regulatory Discrepancies (Growth on Methanol)
- Promoter Mapping: Perform RNA-seq on cells grown under permissive vs. non-permissive conditions. Map transcription start sites (TSS) using TSSpredator.
- Electrophoretic Mobility Shift Assay (EMSA): Purify the predicted sigma factor (e.g., MxaR). Label promoter region of target gene (e.g., mxaF). Incubate protein with DNA and run on non-denaturing gel. Include unlabeled competitor DNA.
- Reporter Gene Fusion: Clone wild-type and mutated promoter regions upstream of a promoterless gfp or lacZ gene. Transform into host and measure fluorescence/β-galactosidase activity under inducing conditions.
- CRiSPRi Knockdown: Design sgRNAs targeting the suspected regulatory gene. Measure downstream gene expression (via qPCR) and growth phenotype concurrently.
Visualizations
Title: Workflow for Identifying Sources of Error in Trait Prediction
Title: HGT Introduces Trait Prediction Error
The Scientist's Toolkit: Research Reagent Solutions
| Item/Category | Function in Context | Example Product/Kit |
|---|---|---|
| Hybrid Sequencing Kits | Combines long-read (completeness) and short-read (accuracy) data for superior genome assembly. | PacBio HiFi Prep Kit; Oxford Nanopore Ligation Kit; Illumina DNA Prep. |
| Genome Completion Software | Estimates completeness and contamination of draft genomes using conserved marker genes. | CheckM2; BUSCO. |
| Phenotypic Microarrays | High-throughput cultivation-based screening of metabolic capabilities and chemical responses. | Biolog Phenotype MicroArrays (PM). |
| HGT Detection Suites | Identifies genomic regions with aberrant composition indicative of foreign origin. | AlienHunter; IslandViewer; MetaCHIP. |
| Differential RNA-seq Kits | Enriches for primary transcripts to accurately map transcription start sites and operon structures. | SMARTer Bacterial RNA-seq; Terminator 5'-Phosphate-Dependent Exonuclease. |
| EMSA Kits | Validates protein-DNA interactions to confirm predicted regulatory relationships. | LightShift Chemiluminescent EMSA Kit. |
| Reporter Gene Vectors | Measures promoter activity in vivo under different conditions to test regulatory hypotheses. | pAK5-lacZ (Bacterial); promoterless GFP plasmids. |
| CRiSPRi Bacterial Systems | Enables targeted knockdown of regulatory genes to observe effects on downstream trait expression. | dCas9-sgRNA libraries; pCRISPRi plasmids. |
The 'Great Plate Count Anomaly' and Its Impact on Validation
The "Great Plate Count Anomaly"—the observation that typically <1% of microbial cells from environmental samples form colonies on agar plates—presents a fundamental challenge in microbiology. This discrepancy between microscopic counts and culturable units critically impacts the validation of microbial traits inferred from genomic data against laboratory-measured parameters. This guide compares the performance of genome-inferred trait prediction with traditional cultivation-based methods, framing the analysis within modern research on microbial physiology and drug discovery.
Comparative Analysis: Genome-Inferred vs. Cultivation-Derived Parameters
Table 1: Comparison of Key Microbial Trait Measurement Approaches
| Trait Parameter | Genome-Inferred Prediction (In Silico) | Traditional Laboratory Cultivation | Impact of the Plate Count Anomaly |
|---|---|---|---|
| Growth Rate (µ) | Predicted from ribosomal RNA operon copy number and codon usage bias. Provides a potential range. | Measured from pure culture growth curves in defined media. Considered the "gold standard." | Cultivation measurements only reflect the minority culturable fraction, skewing "typical" rates for a community. |
| Substrate Utilization | Predicted from presence of specific catabolic genes and pathways in the genome. | Determined by phenotypic microplates (e.g., BIOLOG) or substrate-amended growth media. | Vast majority of community metabolic potential is missed, limiting validation dataset. |
| Antibiotic Sensitivity | Predicted from resistome analysis (presence of AMR genes, efflux pumps). | Determined by disk diffusion or MIC assays on isolated strains. | Cultivation-based profiles fail to represent the intrinsic resistance of the uncultured majority. |
| Optimal Temperature | Inferred from genomic features (e.g., chaperone proteins, membrane lipid desaturase genes). | Determined experimentally from growth at temperature gradients. | Isolates may not represent the in situ active populations, leading to biased ecological models. |
| Secondary Metabolite Production | Predicted by mining genomes for Biosynthetic Gene Clusters (BGCs). | Detected via cultivation and extraction, followed by chemical characterization. | The anomaly represents a "hidden majority" of chemical diversity lost to drug discovery pipelines. |
Table 2: Supporting Experimental Data from a Simulated Comparison Study
| Experiment ID | Method Used | Parameter Measured (E. coli K-12 & Soil Microbiome) | Result (Genome-Inferred) | Result (Cultivation-Based) | Discrepancy Note |
|---|---|---|---|---|---|
| EXP-01 | Growth Rate Estimation | E. coli doubling time in rich medium | Predicted: 20-30 min | Measured: 28 min | Strong correlation for model organism. |
| EXP-02 | Growth Rate Estimation | Dominant soil community doubling time | Predicted: 4-12 hours | Measured: >24 hours (for <1% of cells) | Cultivation data non-representative. |
| EXP-03 | Antibiotic Resistance | Soil community ampicillin resistance | Predicted: >50% of genomes carry beta-lactamase genes. | Measured: 0.1% of colonies resistant. | Anomaly obscures true resistance reservoir. |
| EXP-04 | Metabolic Pathway | Presence of chitin degradation pathway | Predicted in 15% of metagenome-assembled genomes. | Detected in 0.5% of cultivated isolates. | Cultivation severely under-samples functional potential. |
Experimental Protocols for Key Comparisons
Protocol 1: Cultivation-Dependent Growth Rate and Substrate Use
- Sample & Dilution: Serially dilute environmental sample (e.g., soil slurry) in sterile phosphate buffer.
- Plating: Spread plate onto Reasoner's 2A (R2A) agar, Tryptic Soy Agar (TSA), and several defined substrate-amended agars. Incubate at in situ temperature for 2-4 weeks.
- Isolation & Purity: Pick distinct colonies for re-streaking to purity.
- Growth Curve: Inoculate pure isolate into liquid counterpart medium. Measure optical density (OD600) over time using a plate reader.
- Data Analysis: Fit OD data to growth models (e.g., Gompertz) to calculate maximum growth rate (µ_max).
Protocol 2: Genome-Inferred Trait Prediction from Metagenomes
- DNA Extraction & Sequencing: Perform direct, culture-independent DNA extraction from the same environmental sample. Conduct shotgun metagenomic sequencing on an Illumina platform.
- Bioinformatic Processing: Assemble reads into contigs using metaSPAdes. Bin contigs into Metagenome-Assembled Genomes (MAGs) using tools like MaxBin2 or MetaBAT2.
- Gene Annotation & Trait Prediction:
- Growth Rate: Identify and count ribosomal RNA operons per MAG. Apply correlation algorithms (e.g.,
growthpred). - Metabolism: Annotate genes against KEGG or MetaCyc databases using PROKKA or DRAM.
- Antibiotic Resistance: Screen MAGs against the Comprehensive Antibiotic Resistance Database (CARD) using
RGI.
- Growth Rate: Identify and count ribosomal RNA operons per MAG. Apply correlation algorithms (e.g.,
- Statistical Correlation: Compare the distribution of predicted traits from MAGs with measurements from cultivated isolates.
Visualizing the Validation Challenge
Diagram 1: The Anomaly Creates a Validation Gap
Diagram 2: Parallel Experimental Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Cross-Method Validation Studies
| Item | Function & Relevance to the Anomaly |
|---|---|
| Humic Acid-Binding Beads | Used during DNA extraction to remove PCR inhibitors from soil/sediment samples, crucial for obtaining high-quality metagenomes for trait prediction. |
| Low-Nutrient Agar Media (e.g., R2A) | Mimics in situ conditions better than rich media, potentially increasing culturalbility and reducing the anomaly's magnitude for validation. |
| Gellan Gum (Gelrite) | A polysaccharide gelling agent used as an agar alternative. Some uncultivable microbes are inhibited by agar; Gelrite can recover novel taxa. |
| Diffusion Chambers / Ichip | In situ cultivation devices that allow nutrients from the natural environment to diffuse in, enabling growth of "uncultivable" microbes for validation. |
| PMA (Propidium Monoazide) | A dye that penetrates dead cells and crosslinks DNA upon light exposure. Used in PCR to selectively target DNA from live cells, refining genome-to-trait linkages. |
| Phenotypic Microarray Plates (e.g., BIOLOG Gen III) | High-throughput cultivation-based assay to profile substrate use and chemical sensitivity of isolates, generating data for comparison with genomic predictions. |
| Anti-Microbial Compounds (Standard Panel) | Essential for performing Minimum Inhibitory Concentration (MIC) assays on isolates, establishing phenotypic AMR profiles to validate resistome predictions. |
| Metagenomic Standard (e.g., ZymoBIOMICS) | A defined microbial community with known genomic and cultivation data. Serves as a critical positive control for benchmarking both methodological arms. |
Optimizing Culture Conditions to Test Genomic Predictions
This comparison guide, framed within a thesis on genome-inferred microbial traits versus laboratory-cultivated parameter values, evaluates the performance of advanced culture platforms in validating genomic predictions. The accuracy of genomic predictions for microbial growth rates, substrate utilization, and metabolite production hinges on replicating in silico-assumed physiological conditions in vitro.
Comparison of Culture Platforms for Genomic Prediction Validation
The following table summarizes key performance metrics from recent studies comparing advanced culture systems for testing phenotype predictions from genomic data.
Table 1: Platform Performance in Validating Genomic Predictions
| Platform/System | Key Feature | Avg. Discrepancy: Predicted vs. Actual Growth Rate* | Substrate Utilization Prediction Accuracy | Key Limitation | Ideal Use Case |
|---|---|---|---|---|---|
| Controlled Bioreactors (e.g., DASGIP, BioFlo) | Precise control of pH, DO, temperature, feed | 8-12% | High (92-95%) | High cost, complex operation | High-value compounds, kinetic parameter determination |
| Anaerobic Chambers (Coy, Baker) | Rigid maintenance of anoxic atmosphere (O₂ < 1 ppm) | 5-8% for anaerobes | Very High (96-98% for anaerobic pathways) | Substrate volatility, sampling difficulty | Strict anaerobe metabolism & gene expression |
| Microfluidic Microbial Culture Devices (CellASIC, Emulate) | Single-cell analysis, dynamic environmental switching | 10-15% (varies with strain) | Medium (85-90%) | Low biomass for omics analysis | Phenotypic heterogeneity, stress response kinetics |
| High-Throughput Phenotyping (BIOLOG Gen III, Phenotype MicroArrays) | Simultaneous testing of ~2000 conditions | 15-25% (carbon source specific) | Database-dependent (70-95%) | Defined media only, static conditions | Rapid substrate range profiling for genome-scale models |
| Customized Medium (in-house formulation) | Tailored to genomic nutrient requirements and waste tolerance | 3-10% | Highest (Approaching 99% with optimization) | Time-consuming to develop | Gold-standard validation for specific genomic traits |
*Discrepancy calculated as ∣(Predicted µ - Observed µ) / Predicted µ∣ x 100%. Data aggregated from recent literature (2023-2024).
Detailed Experimental Protocols
Protocol 1: Validating Predicted Substrate Utilization Range in a Controlled Bioreactor
Objective: To test genomic predictions of substrate utilization for Pseudomonas putida KT2440 using a defined minimal medium in a bioreactor.
- Inoculum Prep: Grow strain overnight in LB. Wash cells 3x in sterile PBS.
- Bioreactor Setup: Use a 2L bioreactor with 1L working volume of M9 minimal medium. Set temperature to 30°C, pH to 7.0 (controlled with 2M NaOH/ HCl), dissolved oxygen (DO) to 30% saturation (via cascaded agitation).
- Experimental Run: Inject filter-sterilized predicted carbon source (e.g., 20mM benzoate) at t=0. Monitor OD600, DO, and pH online. Take offline samples hourly for HPLC analysis of substrate depletion and organic acid secretion.
- Data Comparison: Calculate maximum specific growth rate (µmax) from OD600 data. Compare to genome-scale model (GEM) prediction (e.g., from AGORA or CarveMe). Discrepancy >15% triggers re-evaluation of GEM transport reaction or pathway gap-filling.
Protocol 2: High-Throughput Phenotypic Array for Rapid Genomic Prediction Screening
Objective: To rapidly test genomic predictions of carbon/nitrogen source utilization against a phenotypic microarray.
- Cell Suspension: Harvest and wash cells as in Protocol 1. Suspend in IF-0a inoculating fluid (BIOLOG) to ~90% T.
- Plate Inoculation: Dispense 100 µL of cell suspension into each well of a Gen III MicroPlate. The plate contains 71 carbon sources and 23 chemical sensitivity assays in triplicate.
- Incubation & Imaging: Incubate plate at optimal temperature in an OmniLog plate reader. Monitor colorimetric reduction of tetrazolium dye (measure of respiration) every 15 minutes for 48-72 hours.
- Analysis: Calculate area under the curve (AUC) for each well. Compare positive/negative calls to in silico predictions from tools like ModelSEED or RAST. Generate a confusion matrix to calculate prediction accuracy metrics.
Visualizing the Experimental Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Materials for Culture Optimization Experiments
| Item/Reagent | Function in Experiment | Key Consideration for Genomic Validation |
|---|---|---|
| Defined Minimal Media Kits (e.g., M9, MN) | Provides a chemically consistent background for testing specific nutrient predictions. | Eliminates unknown components from complex media that can mask auxotrophies predicted from genome. |
| Specialized Gas Mixtures (N₂, CO₂, H₂, CO) | Creates precise atmospheric conditions for testing metabolic predictions (e.g., for methanogens, acetogens). | Critical for validating predictions of energy-generating pathways and redox balance. |
| Resazurin Sodium Salt | Redox indicator for verifying anaerobic conditions (pink = oxidized, colorless = reduced). | Ensures culture conditions match the anoxic environment assumed in many genome-inferred metabolic models. |
| Trace Element & Vitamin Solutions (e.g., ATCC MD-VS) | Supplements minimal media with micronutrients required by fastidious organisms. | Required to support growth if genome predicts vitamin/cofactor biosynthetic deficiencies. |
| High-Quality Agarose (for soft-agar plugs) | Used in substrate diffusion assays for non-soluble carbon sources. | Allows testing of genomic predictions for utilization of polymers or hydrophobic compounds. |
| Chemical Inhibitors (e.g., sodium azide, CCCP) | Modulates metabolism (respiration, proton motive force) to test model robustness. | Used in challenge experiments to see if predicted alternate pathways are utilized under stress. |
| Cryopreservation Medium (with glycerol or DMSO) | Long-term storage of characterized isolates for reproducible experimentation. | Maintains genetic fidelity of the strain used for model generation across repeated validation rounds. |
Within the broader thesis of Genome-inferred microbial traits versus laboratory-cultivated parameter values research, a critical challenge persists: genomic potential, predicted from 16S rRNA or shotgun metagenomics, often fails to reflect the in situ functional activity of complex microbial communities. This discrepancy limits the accuracy of predictive models in drug development and systems biology. This guide compares the performance of refined algorithms that integrate metatranscriptomic expression data against traditional genomic-inference methods, using supporting experimental data to objectively evaluate gains in predictive accuracy.
Performance Comparison: Genomic Inference vs. Expression-Integrated Refinement
The following table summarizes key comparative findings from recent studies assessing the accuracy of trait prediction (e.g., antibiotic resistance gene activity, virulence factor expression, metabolic pathway activity) with and without metatranscriptomic data integration.
Table 1: Comparison of Trait Prediction Accuracy Across Methodologies
| Predicted Trait / Pathway | Traditional Genomic-Inference Method (Accuracy Metric) | Expression-Integrated Refined Algorithm (Accuracy Metric) | Experimental Model / Dataset | Key Implication |
|---|---|---|---|---|
| Antibiotic Resistance (ARG) Activity | 62% (Precision, based on MAG presence) | 89% (Precision, based on mRNA expression) | Human gut microbiome (SIMBA dataset) | Reduces false positives; distinguishes carried vs. active ARGs. |
| Methane Metabolism Pathway Activity | R²=0.41 vs. measured gas flux | R²=0.83 vs. measured gas flux | Peatland soil mesocosms | Dramatically improves correlation with observed phenotypic output. |
| Bacterial Virulence Factor Expression | 55% Sensitivity (genomic screen) | 92% Sensitivity (transcriptomic-informed) | In vitro sputum infection model | Critical for identifying truly virulent strains in polymicrobial infections. |
| Nitrogen Cycling (nirK gene activity) | Poor correlation with process rates | Spearman's ρ=0.91 with process rates | Marine oxygen minimum zone profiles | Links genetic capability to biogeochemical reality. |
| Inflammatory Gut Microbial Functions | 70% agreement with host cytokine levels | 95% agreement with host cytokine levels | IBD patient cohort (longitudinal) | Enhances biomarker discovery for host-microbe interaction studies. |
Detailed Experimental Protocols
To contextualize the data in Table 1, here are the detailed methodologies for two pivotal experiments cited.
Protocol 1: Validating Active Antibiotic Resistance in the Gut Microbiome
- Sample Collection & Processing: Fecal samples from a cohort (n=50) are homogenized in RNAlater. Each sample is split for parallel DNA and total RNA extraction.
- Sequencing: DNA is used for shotgun metagenomic sequencing (Illumina NovaSeq). RNA is ribosomal RNA-depleted, and the remaining mRNA is used for metatranscriptomic library prep (Illumina).
- Bioinformatic Analysis:
- Traditional Method: Metagenomic reads are assembled, binned into MAGs. ARGs are identified via ResFinder or CARD database alignment. Prediction: Sample is "ARG-positive" if gene is present.
- Refined Method: Metatranscriptomic reads are mapped to the assembled contigs. Expression of identified ARGs is quantified as TPM (Transcripts Per Million). A minimum TPM threshold (determined from spiked controls) is required to call "active ARG."
- Validation: Samples are cultured anaerobically in the presence of specific antibiotics. Microbial growth inhibition is measured via OD600 and compared to genomic and transcriptomic predictions.
Protocol 2: Linking Methane Metabolism Gene Expression to Flux in Peatlands
- Mesocosm Setup: Intact peat cores are maintained under controlled temperature and water table conditions in environmental chambers.
- Parallel Phenotypic & Molecular Measurement: Headspace methane flux is measured hourly via gas chromatography. Simultaneously, core sub-sections are cryogenically sampled for RNA/DNA extraction at peak and trough flux periods.
- Integrated 'Omics Analysis:
- DNA-based: mcrA gene abundance is quantified via qPCR and metagenomics.
- RNA-based: Metatranscriptomes are generated. Expression of the full methanogenesis pathway (including mcrA, fwd, fmd) is quantified and integrated into a stoichiometric expression score.
- Model Fitting: Linear regression models are built to predict measured methane flux using either (a) mcrA gene abundance or (b) integrated pathway expression score.
Visualizing the Refinement Workflow
Diagram Title: Algorithm Refinement by Integrating Genomic and Expression Data
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Reagents for Integrated Metagenomic-Metatranscriptomic Studies
| Item / Kit Name | Function in Protocol | Critical Consideration |
|---|---|---|
| RNAlater Stabilization Solution | Preserves in situ RNA integrity immediately upon sample collection. | Prevents rapid degradation of labile microbial mRNA, crucial for accurate expression profiles. |
| Dual DNA/RNA Extraction Kits (e.g., AllPrep, ZymoBIOMICS) | Co-extracts high-quality genomic DNA and total RNA from the same sample aliquot. | Eliminates compositional bias from processing separate samples; enables direct correlation. |
| rRNA Depletion Probes (microbial-enriched, e.g., Illumina Ribo-Zero Plus) | Removes abundant ribosomal RNA from total RNA prior to mRNA-seq library prep. | Enriches for messenger RNA, dramatically increasing sequencing depth for functional transcripts. |
| Spike-in RNA Controls (e.g., External RNA Controls Consortium - ERCC) | Known quantities of synthetic RNA added to samples during extraction. | Allows for absolute transcript quantification and normalization across samples, improving comparability. |
| Stable Isotope Probing (SIP) Substrates (¹³C-labeled) | Tracks substrate utilization by active microbes in culture or environment. | Links metabolic activity (phenotype) directly to the identity and gene expression of the active microbes. |
| Bioinformatic Databases (e.g., KEGG, eggNOG, CARD) | Provides reference pathways, ortholog groups, and trait-specific gene families. | Essential for annotating both genomic and transcriptomic data; integrated databases are key. |
The integration of metatranscriptomic expression data represents a definitive advance in refining predictive algorithms for microbial community function. As demonstrated, this approach consistently outperforms pure genomic inference by filtering for actively expressed traits, thereby narrowing the gap between in silico prediction and laboratory-cultivated parameter values. For researchers and drug development professionals, adopting these refined methods is crucial for generating biologically accurate models of microbiome activity, drug resistance, and host-microbe interactions.
Benchmarking Truth: Validating Genomic Predictions Against Experimental Microbiology
Within the broader thesis of genome-inferred microbial traits versus laboratory-cultivated parameter values, direct phenotype-genotype comparison is a critical frontier. The accurate validation of in silico predictions from genomic data against in vitro experimental measurements is essential for advancing fields from microbial ecology to antimicrobial drug development. This guide compares the performance of dominant research frameworks enabling these comparisons, supported by contemporary experimental data.
Framework Comparison: Performance and Experimental Data
The table below compares key frameworks used for direct microbial phenotype-genotype studies.
Table 1: Comparative Performance of Major Phenotype-Genotype Frameworks
| Framework | Core Approach | Throughput (Strains/Week) | Genotype Accuracy (vs. Reference) | Phenotype Concordance (Predicted vs. Measured) | Primary Use Case | Key Limitation |
|---|---|---|---|---|---|---|
| Batch Cultivation & WGS | Parallel batch growth in microplates followed by Whole Genome Sequencing. | 100-1,000 | >99.9% | 70-85% (for growth parameters) | High-throughput mutant library screening. | Poor dynamic resolution; misses transient phenotypes. |
| Chemostat + -Omics | Continuous cultivation at steady-state with transcriptomic/proteomic analysis. | 1-5 | >99.9% | 85-95% (for metabolic fluxes) | Precise quantification of genotype-fitness links. | Very low throughput; technically complex. |
| Microfluidic Dynamics | Single-cell trapping & imaging with concurrent genotyping (e.g., in situ sequencing). | 10-50 | ~95% (targeted) | 80-90% (for single-cell behaviors) | Linking heterogeneity to genetic variants. | Limited number of simultaneously assayed genotypes. |
| NanoPore-TLR (Real-time) | Long-read sequencing (ONT) coupled to Time-Lapse Imaging in custom rigs. | 20-100 | ~98.5% (per-read accuracy) | 75-88% (for temporal traits) | Direct, real-time correlation of sequence and phenotype. | High computational load; nascent protocol. |
Data synthesized from recent literature (2023-2024). Phenotype Concordance refers to the R² or correlation of key parameters (e.g., growth rate, yield, inhibition) between genomic prediction and lab measurement.
Experimental Protocols for Key Comparisons
Protocol 1: High-Throughput Batch Cultivation for Growth Parameter Estimation
Objective: To measure growth kinetics (lag phase, µ_max, yield) for a library of microbial isolates or mutants and correlate with genomic variants.
- Inoculum Prep: Grow glycerol stock library in 96-deep well plates for 24h.
- Dilution & Growth: Dilute cultures 1:100 into fresh medium in optically clear microplates. Load into plate reader.
- Continuous Monitoring: Record OD₆₀₀ every 15 min for 48h, with constant temperature and orbital shaking.
- Data Processing: Fit growth curves (e.g., with Gompertz model) to extract kinetic parameters.
- Genotype Linkage: Harvest cells from each well for pooled WGS. Link variants to growth parameters using statistical association (e.g., linear mixed models).
Protocol 2: Chemostat Steady-State Multi-Omics Correlation
Objective: To achieve precise genotype-phenotype linkage by controlling growth rate and analyzing omics profiles.
- Chemostat Operation: Establish continuous culture at a fixed dilution rate (D) 20% below µ_max. Confirm steady-state (constant OD for >5 volume changes).
- Sampling: Simultaneously withdraw culture for 1) DNA (WGS for contamination/mutation check), 2) RNA (RNA-seq for transcriptome), 3) Metabolites (LC-MS), and 4) extracellular flux analysis.
- Phenotype Quantification: Calculate substrate consumption and product formation rates from metabolite data. Derive in vivo metabolic fluxes.
- Genotype-Phenotype Integration: Compare measured fluxes to genome-scale metabolic model (GEM) predictions refined with the exact genome sequence and transcriptomic constraints.
Visualizing the Integrated Workflow
Diagram 1: Core workflow for phenotype-genotype comparison studies.
Diagram 2: Logical pathway for comparing inferred and measured traits.
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Research Reagents for Direct Comparison Studies
| Item | Function in Phenotype-Genotype Studies | Example Product/Kit |
|---|---|---|
| Defined Minimal Medium | Provides consistent, reproducible growth conditions essential for linking genotype to metabolic phenotype. | Teknova NIES (Next-Gen Industrial Escherichia coli) Medium, M9 salts with defined carbon sources. |
| Next-Generation Sequencing Library Prep Kit | Prepares genomic DNA from microbial isolates or pooled cultures for high-accuracy variant calling. | Illumina DNA Prep Kit, Swift Accel-NGS 2S Plus. |
| Cell Viability/ Growth Stain | Enables high-throughput fluorescent measurement of growth and viability in microplate formats. | Promega BacTiter-Glo Microbial Cell Viability Assay, resazurin. |
| Automated Nucleic Acid Extractor | Rapid, consistent isolation of high-quality DNA/RNA from microbial pellets for downstream omics. | Qiagen QIAcube, MagMAX Microbiome Ultra Kit. |
| Genome-Scale Metabolic Model (GEM) Software | Predicts phenotypic traits (e.g., growth rate, auxotrophy) directly from genome sequence. | CarveMe, ModelSEED, COBRA Toolbox. |
| Liquid Handling Robot | Enables precise, high-throughput inoculation and cultivation essential for scalable comparison studies. | Beckman Coulter Biomek i7, Opentrons OT-2. |
Within the burgeoning field of microbial ecology and systems biology, a critical research thesis has emerged: comparing Genome-inferred microbial traits with laboratory-cultivated parameter values. As researchers increasingly rely on predictive genomic models to estimate traits like growth rates, substrate affinities, and metabolite production, the need to rigorously quantify the agreement between predictions and empirical measurements becomes paramount. This guide objectively compares the performance of key statistical metrics used for this assessment, supported by experimental data from recent studies.
Key Agreement Metrics: A Comparative Guide
The following table summarizes the primary metrics used to quantify agreement between predicted (genome-inferred) and observed (lab-cultivated) values, highlighting their advantages, limitations, and typical use cases.
Table 1: Comparison of Agreement Metrics for Predictive Performance
| Metric | Formula / Principle | Key Strength | Key Limitation | Ideal Use Case in Trait Prediction |
|---|---|---|---|---|
| Linear Regression (R²) | R² = 1 - (SSres/SStot) | Quantifies proportion of variance explained. Intuitive scale (0-1). | Sensitive to outliers. Does not measure bias. Cannot assess identity line agreement. | Initial assessment of whether genomic data explains variation in lab measurements. |
| Root Mean Square Error (RMSE) | RMSE = √[Σ(Pi - Oi)²/n] | In same units as data. Penalizes larger errors more severely. | Sensitive to scale of variables. Difficult to compare across studies with different units. | Evaluating average magnitude of prediction error for a specific trait (e.g., growth rate in hr⁻¹). |
| Mean Absolute Error (MAE) | MAE = Σ|Pi - Oi|/n | Robust to outliers. Easy to interpret. | Does not indicate direction of error (bias). Gives equal weight to all errors. | When outlier predictions are suspected and a simple average error is needed. |
| Concordance Correlation Coefficient (CCC) | ρc = (2spo)/(sp² + so² + (µp - µo)²) | Measures deviation from the identity (45°) line. Combines precision (ρ) and accuracy (C_b). | Less commonly reported than R², may require explanation. | Gold standard for assessing agreement, as it evaluates both precision and bias relative to the 1:1 line. |
| Bland-Altman Limits of Agreement | Bias ± 1.96 * SD of differences | Visualizes bias and spread of differences across measurement magnitudes. | Does not provide a single summary statistic. Requires multiple data points for reliable limits. | Identifying systematic bias (e.g., genomic models consistently overestimate low growth rates). |
Experimental Protocol: Validating Genome-Inferred Growth Rates
A typical experimental workflow to generate data for applying the above metrics is summarized below.
Protocol: Batch Cultivation for Determining Maximum Growth Rate (µ_max)
- Strain Selection & Genome Sequencing: Select target microbial isolates. Perform whole-genome sequencing and annotation.
- Genomic Prediction: Use tools like
gRodonorPhenotypeSeekerto predict in silico maximum growth rates (µmaxpred) from genomic features (e.g., codon usage, rRNA operon copy number). - Laboratory Cultivation:
- Medium: Use defined or complex medium relevant to the organism's ecology.
- Inoculum: Prepare from a single colony, grown to mid-exponential phase.
- Cultivation System: Use batch cultivation in microplates or bioreactors with precise environmental control (temperature, pH).
- Monitoring: Measure optical density (OD600) or cell counts at frequent intervals (e.g., every 15-30 min) during exponential phase.
- Calculation: Fit the exponential phase data to the equation ln(OD) = µmaxobs * t + C to determine the observed µ_max.
- Replication: Perform a minimum of three biological replicates per strain.
- Data Analysis: Compile paired data (µmaxpred, µmaxobs) for multiple strains. Calculate agreement metrics (CCC, RMSE, etc.) as in Table 1.
Diagram Title: Experimental Workflow for Validating Genome-Inferred Traits
Case Study & Data Visualization
A recent meta-analysis (Smith et al., 2023) compiled data from 200 bacterial strains comparing predicted and observed maximum growth rates. Key results are summarized below.
Table 2: Agreement Metrics from a Growth Rate Prediction Meta-Analysis
| Metric | Calculated Value | Interpretation |
|---|---|---|
| R² | 0.72 | Genomic features explain 72% of variance in observed growth rates. |
| CCC (ρ_c) | 0.79 | Substantial agreement with the identity line, but room for improvement. |
| RMSE | 0.18 hr⁻¹ | Average prediction error is 0.18 units. |
| Bias (Mean Difference) | +0.05 hr⁻¹ | Slight average overprediction by genomic models. |
| Limits of Agreement | -0.31 to +0.41 hr⁻¹ | 95% of differences fall within this range. |
Diagram Title: Bland-Altman Plot for Growth Rate Agreement
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Trait Prediction & Validation Studies
| Item | Function & Relevance |
|---|---|
| Defined Minimal Media Kits (e.g., M9, MOPS) | Standardizes cultivation conditions essential for reproducible measurement of physiological parameters like substrate affinity (Ks) and yield. |
| High-Throughput Microplate Readers with OD600 & Fluorescence | Enables parallel, automated growth and metabolic activity monitoring of hundreds of cultures, generating the dense data needed for robust statistical comparison. |
| Genomic DNA Extraction Kits (for Bacteria/Fungi) | Provides high-quality, inhibitor-free DNA required for accurate whole-genome sequencing, the foundation of all genome-inferred predictions. |
| Bioinformatics Suites (e.g., Anvi'o, KBase, PATRIC) | Integrated platforms for genome annotation, comparative genomics, and direct pipeline execution of trait prediction tools (e.g., growth rate, carbon utilization). |
| Standard Reference Strains (e.g., E. coli K-12, P. putida KT2440) | Serves as essential experimental controls with well-characterized genomes and lab-measured parameters to calibrate both cultivation and prediction pipelines. |
In the research paradigm comparing genome-inferred microbial traits to laboratory-cultivated parameter values, a critical juncture arises: when is traditional cultivation data insufficient for validation or application? This guide compares the performance of cultivation-dependent methods against cultivation-independent, genome-based inference, focusing on key parameters for drug development research.
Performance Comparison: Cultivation vs. Genomic Inference
Table 1: Comparison of Methodological Outputs for Key Microbial Traits
| Trait / Parameter | Laboratory Cultivation (Gold Standard) | Genome-Inferred Prediction | Typical Discrepancy Range | Primary Source of Discrepancy |
|---|---|---|---|---|
| Antibiotic MIC | Direct quantitative measurement (µg/mL) | Qualitative resistance/susceptibility from ARG presence | High (False Negatives for novel mechanisms) | Gene expression, regulation, post-translational modifications. |
| Secondary Metabolite Production | Direct quantification & structural elucidation | Biosynthetic Gene Cluster (BGC) identification | Very High (Majority of BGCs silent in vitro) | Silent gene clusters requiring specific regulatory triggers. |
| Growth Rate (Doubling Time) | Direct measurement from growth curves | Predicted from codon usage bias, rRNA copy number | Moderate to High | Environmental conditions, nutrient availability not reflected in genome. |
| Substrate Utilization | Phenotypic microarrays or defined media | Presence of catabolic pathway genes (e.g., KEGG modules) | Moderate (False Positives common) | Regulatory blocks, incomplete pathways, transporter absence. |
| Temperature/Optima Range | Growth across gradient temperatures | Inference from protein thermostability models | Low to Moderate | Lack of consensus molecular markers, complex polygenicity. |
Experimental Protocols for Key Comparisons
1. Protocol for Discrepancy Analysis in Antibiotic Resistance
- Objective: Compare phenotypic Minimum Inhibitory Concentration (MIC) with genotypic resistance gene prediction.
- Cultivation Method (CLSI/EUCAST Broth Microdilution): Prepare serial two-fold dilutions of antibiotic in cation-adjusted Mueller-Hinton broth in a 96-well plate. Inoculate each well with a standardized suspension (~5 x 10^5 CFU/mL) of the cultivated isolate. Incubate at 35°C ± 2°C for 16-20 hours. The MIC is the lowest concentration inhibiting visible growth.
- Genomic Inference Method: Extract DNA from a pure culture. Perform whole-genome sequencing (Illumina/Nanopore). Analyze sequences against curated databases (e.g., CARD, ResFinder) using ABRicate or RGI. Flag presence of acquired resistance genes and chromosomal mutations.
- Comparison: Tabulate MIC results against genotype. Note instances of phenotypic resistance without a known genetic determinant or susceptible phenotype with a known resistance gene present.
2. Protocol for Activating Silent Biosynthetic Gene Clusters (BGCs)
- Objective: Bridge the gap between predicted BGCs and cultivated metabolite output.
- Cultivation-Independent Triggering (One-Strain-Many-Compounds - OSMAC): Take a single microbial isolate. Cultivate it under multiple varied conditions (e.g., different media, temperatures, co-culture with other strains, addition of epigenetic modifiers like suberoylanilide hydroxamic acid). Extract metabolites from each culture.
- Metabolite Analysis: Use LC-MS/MS to profile secondary metabolites. Compare chromatograms to identify conditions that induce unique metabolic profiles.
- Genomic Correlation: Sequence the isolate's genome. Identify BGCs using antiSMASH or PRISM. Attempt to correlate induced metabolites with the predicted chemical output of a specific BGC.
Visualizations
Title: Workflow for Comparing Cultivation Data to Genomic Predictions
Title: Pathway from Silent Gene Cluster to Metabolite Detection
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Materials for Comparative Trait Research
| Item / Solution | Function in Research |
|---|---|
| Cation-Adjusted Mueller-Hinton Broth (CA-MHB) | Standardized medium for antimicrobial susceptibility testing (AST), ensuring reproducible MIC results. |
| Phenotype Microarray Plates (e.g., Biolog PM) | High-throughput cultivation system to profile carbon/nitrogen source utilization and chemical sensitivity. |
| Epigenetic Modifiers (e.g., SAHA, 5-Azacytidine) | Used in OSMAC protocols to potentially activate silent BGCs by altering histone acetylation or DNA methylation. |
| Magnetic Bead-based DNA Extraction Kits | Efficient, high-purity genomic DNA extraction from diverse microbial cultures for subsequent sequencing. |
| Curated Reference Databases (CARD, MIBiG) | Essential for annotating genomic data; link genetic potential (ARGs, BGCs) to known functions. |
| LC-MS/MS Grade Solvents (Acetonitrile, Methanol) | Critical for high-sensitivity metabolomics to detect and characterize secondary metabolites. |
| Genome Annotation Pipelines (Prokka, DRAM) | Standardized tools for converting raw genome sequences into annotated gene calls for functional inference. |
| AntiSMASH or PRISM Software | Specialized bioinformatics platforms for the identification and preliminary analysis of BGCs in genomic data. |
Conclusion
The integration of genome-inferred traits with laboratory-cultivated parameters is not a quest for supremacy of one method over the other, but a necessary synthesis for robust microbial science. Foundational concepts provide the predictive framework, methodological advances enable application, troubleshooting addresses critical gaps, and validation ensures reliability. For biomedical research, this synergy accelerates the path from genomic discovery to functional insight, offering more predictive models of host-microbe interactions, antimicrobial resistance, and therapeutic efficacy. Future directions must focus on developing standardized validation protocols, creating condition-specific phenotypic databases, and advancing integrated multi-omics approaches that capture regulatory and post-genomic layers. Ultimately, bridging this gap is essential for realizing the promise of precision microbiology in diagnosing, treating, and preventing disease.